Chain-of-Thought Prompting
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, published by Wei et al. in Jan 2022.
- Scaling up the size of LM usually brings improved model performance. However, on challenging tasks such as arithmetic, commonsense and symbolic reasoning, this is not the case.
- We can improve the reasoning ability by generating natural language rationales that lead to the final answer but it is very costly to create a rationale-augmented dataset.
- In-context few-shot learning (prompt the model with a few input-output exemplars) does work for a range of simple tasks, but works poorly on reasoning tasks.
- The paper introduced chain-of-thought prompting, a series of intermediate natural language reasoning steps in the triplet form of <input, chain of thought, output> that leads to the final answer.
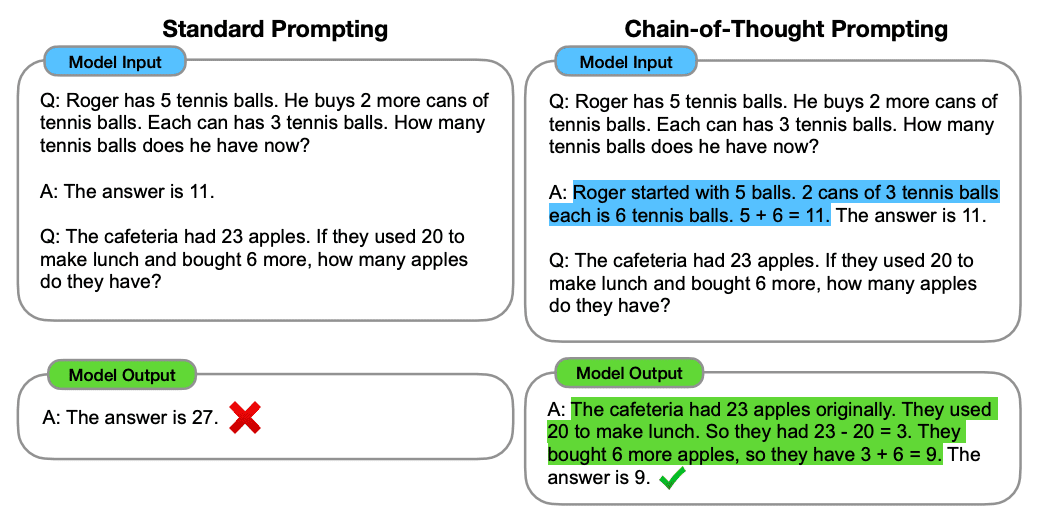
- Experiment Setup: Comparing standard prompting (in-context exemplars of input–output pairs) with CoT prompting (a fixed set of eight few-shot exemplars with CoT)
- Arithmetic Reasoning: CoT prompting does not positively impact performance for small models, and only yields performance gains when used with models of ∼100B parameters. CoT prompting also has larger performance gains for more-complicated problems (i.e. GSM8K dataset).
- Commonsense Reasoning: CoT prompting improves the commonsense reasoning abilities of language models across all model scales. PaLM 540B benefited the most from CoT.
- Symbolic Reasoning: Two tasks (concatenate the last letters of words in a name, answer whether a coin is still hedas up after flip or don’t flip). CoT prompts still outperforms standard prompts, with bigger gap on larger models and OOD tests.
- Overall, CoT prompts is a simple mechanism that can elicit multi-step reasoning behavior in LLMs. For many reasoning tasks where standard prompting has a flat scaling curve in terms of model sizes, CoT prompting leads to dramatically increasing scaling curves.
Chain-of-Thought Prompting with Self Consistency
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, published by Wang et al. in March 2022.
- Wang et al. proposed self-consistency decoding strategy to replace the greedy decoding used in CoT prompting. Self-consistency leverages the intuition that complex reasoning tasks typically admit multiple reasoning paths that reach a correct answer. The more that deliberate thinking and analysis is required for a problem, the greater the diversity of reasoning paths that can recover the answer.
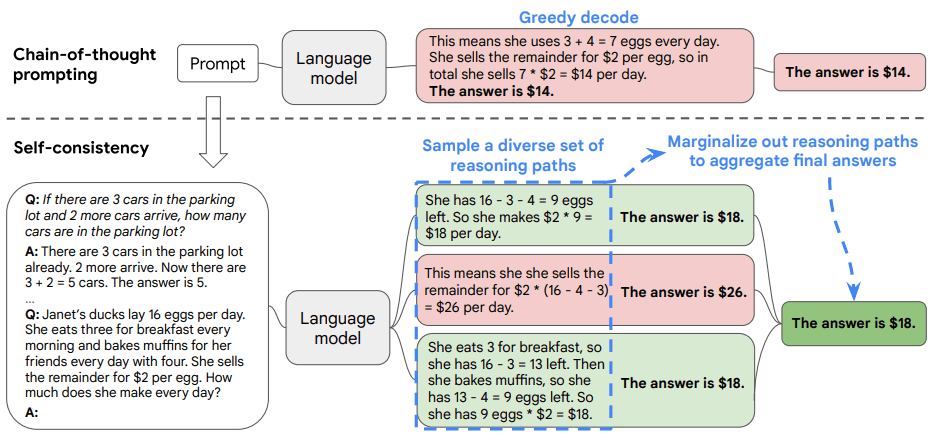
- Self-Consistency method generates a diverse of candidate outputs by sampling the language model’s decoder (e.g. with top k or top p sampling), and then aggregate the answers by marginalizing out the sampled reasoning paths and choosing the answer that is the most consistent among the generated answers.
- How do we marginalize the reasoning path? Each generated text is parsed (with a task-specific parser) into the reasoning path (i.e. She has 16 - 3 - 4 = 9 eggs left. So she makes $2 * 9 =$18 per day) and the answer (i.e. The answeris $18). For each answer, we sum the probability for all observed reasoning path.
- Results: self-consistency boosts the performance of chain-of-thought prompting on a range of popular arithmetic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%). These gains are achieved by sampling and aggregating 40 outputs with Self-Consistency instead a greedy decode of 1.
Let’s think step by step
- Large Language Models are Zero-Shot Reasoners, published by Kojima et al. in May 2022
- While CoT prompting proposed by Wei et al. significantly increased the reasoning capability of LLMs, task-specific exemplars are required. Kojima et al. proposed Zero-shot-CoT, which is to simply add Let’s think step by step to the question to elicit step-by-step reasoning 🤯 !

- Zero-shot-CoT needs to prompt twice to first extract the reasoning with the appended Let’s think step by step and then extract the answers.
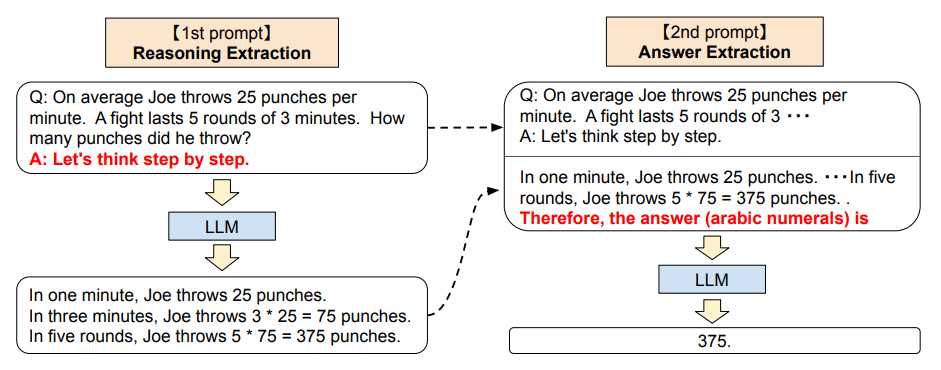
- While Zero-shot-CoT slightly underperforms the CoT proposed by Wei et al. (which requires hand-crafted and task-specific exemplars), it massively outperform the zero shot baseline.
Finetuning with chain-of-thought annotations
-
Scaling Instruction-Finetuned Language Models, published by Chung et al. in late 2022
-
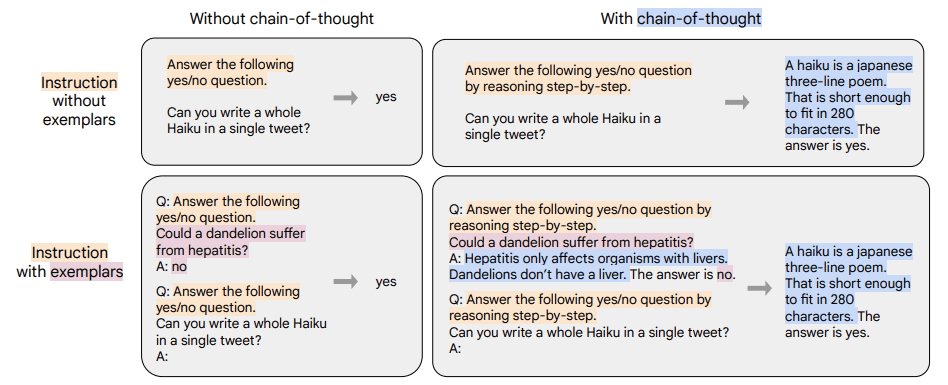
The paper introduces the various Instruction Finetuning techniques (FLAN), among which is CoT finetuning. The goal of CoT Finetuning is to produce an improved model with multi-step reasonining ability in addition to the traditional NLP tasks learned through Instruction Finetuning.
-
Chung et al. created a new mixture of nine datasets from prior work for which human raters manually wrote CoT annotations for a training corpus. These nine datasets include tasks such as arithmetic reasoning, multi-hop reasoning and natural language inference. A mixture of data format (with and without exemplars and CoT) are used for finetuning.
-
Results
- CoT prompting abilities of CoT-finetuned Flan-PaLM outperform PaLM on the held-out evaluation benchmarks.
- Some CoT data is needed to maintain reasoning ability, because finetuning on only non-CoT degrades performance on CoT.
- Running CoT Finetuning both with and without exemplars means that the resulting model can perform CoT reasoning in a zero-shot setting (which can be activated by a phrase like “let’s think step-by-step)